Publications
Selected publications. You can find a full list of publications in my Google Scholar.
2026
2026
-
 Learning to reconstruct from saturated data: audio declipping and high-dynamic range imagingVictor Sechaud , Laurent Jacques , Patrice Abry , and Julian TachellaTMLR, Featured Certification, 2026
Learning to reconstruct from saturated data: audio declipping and high-dynamic range imagingVictor Sechaud , Laurent Jacques , Patrice Abry , and Julian TachellaTMLR, Featured Certification, 2026Learning based methods are now ubiquitous for solving inverse problems, but their deployment in real-world applications is often hindered by the lack of ground truth references for training. Recent self-supervised learning strategies offer a promising alternative, avoiding the need for ground truth. However, most existing methods are limited to linear inverse problems. This work extends self-supervised learning to the non-linear problem of recovering audio and images from clipped measurements, by assuming that the signal distribution is approximately invariant to changes in amplitude. We provide sufficient conditions for learning to reconstruct from saturated signals alone and a self-supervised loss that can be used to train reconstruction networks. Experiments on both audio and image data show that the proposed approach is almost as effective as fully supervised approaches, despite relying solely on clipped measurements for training.
-
-
 Self-Supervised Learning from Noisy and Incomplete DataJulian Tachella, and Mike DaviesFoundations and Trends in Signal Processing, 2026
Self-Supervised Learning from Noisy and Incomplete DataJulian Tachella, and Mike DaviesFoundations and Trends in Signal Processing, 2026 -
 Efficient Unrolled Networks for Large-Scale 3D Inverse ProblemsRomain Vo , and Julian TachellaCVPR 2026, 2026
Efficient Unrolled Networks for Large-Scale 3D Inverse ProblemsRomain Vo , and Julian TachellaCVPR 2026, 2026 -
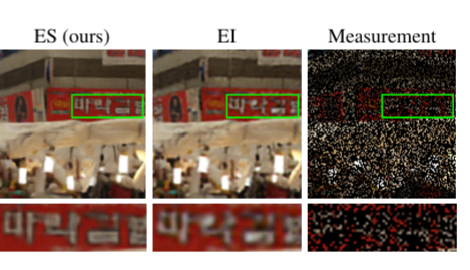 Equivariant Splitting: Self-supervised learning from incomplete dataVictor Sechaud , Jeremy Scanvic , Quentin Barthelemy , Patrice Abry , and Julian TachellaICLR 2026, 2026
Equivariant Splitting: Self-supervised learning from incomplete dataVictor Sechaud , Jeremy Scanvic , Quentin Barthelemy , Patrice Abry , and Julian TachellaICLR 2026, 2026Self-supervised learning for inverse problems allows to train a reconstruction network from noise and/or incomplete data alone. These methods have the potential of enabling learning-based solutions when obtaining ground-truth references for training is expensive or even impossible. In this paper, we propose a new self-supervised learning strategy devised for the challenging setting where measurements are observed via a single incomplete observation model. We introduce a new definition of equivariance in the context of reconstruction networks, and show that the combination of self-supervised splitting losses and equivariant reconstruction networks results in the same minimizer in expectation as the one of a supervised loss. Through a series of experiments on image inpainting, accelerated magnetic resonance imaging, and compressive sensing, we demonstrate that the proposed loss achieves state-of-the-art performance in settings with highly rank-deficient forward models.
-
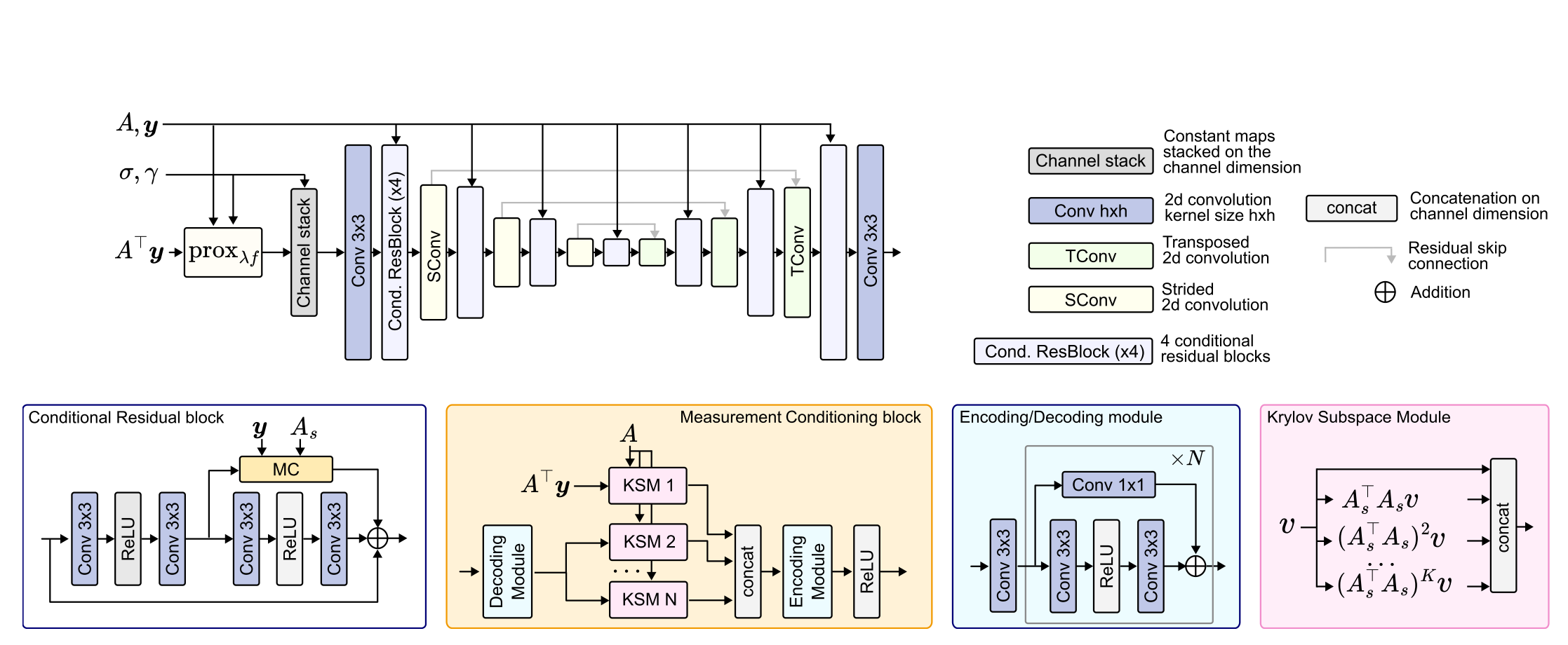 Reconstruct Anything Model: a lightweight foundational model for computational imagingMatthieu Terris , Samuel Hurault , Maxime Song , and Julian TachellaICLR 2026, 2026
Reconstruct Anything Model: a lightweight foundational model for computational imagingMatthieu Terris , Samuel Hurault , Maxime Song , and Julian TachellaICLR 2026, 2026Most existing learning-based methods for solving imaging inverse problems can be roughly divided into two classes: iterative algorithms, such as plug-and-play and diffusion methods, that leverage pretrained denoisers, and unrolled architectures that are trained end-to-end for specific imaging problems. Iterative methods in the first class are computationally costly and often provide suboptimal reconstruction performance, whereas unrolled architectures are generally specific to a single inverse problem and require expensive training. In this work, we propose a novel non-iterative, lightweight architecture that incorporates knowledge about the forward operator (acquisition physics and noise parameters) without relying on unrolling. Our model is trained to solve a wide range of inverse problems beyond denoising, including deblurring, magnetic resonance imaging, computed tomography, inpainting, and super-resolution. The proposed model can be easily adapted to unseen inverse problems or datasets with a few fine-tuning steps (up to a few images) in a self-supervised way, without ground-truth references. Throughout a series of experiments, we demonstrate state-of-the-art performance from medical imaging to low-photon imaging and microscopy.






2025
2025
-
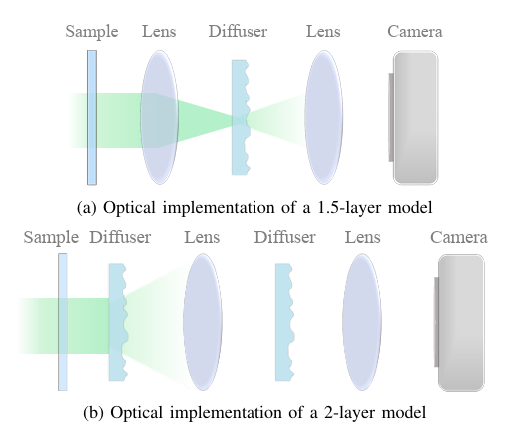 Structured Random Models for Phase Retrieval with Optical DiffusersZhiyuan Hu , Fakhriyya Mammadova , Julian Tachella, Michael Unser , and Jonathan Dong2025
Structured Random Models for Phase Retrieval with Optical DiffusersZhiyuan Hu , Fakhriyya Mammadova , Julian Tachella, Michael Unser , and Jonathan Dong2025Phase retrieval is a nonlinear inverse problem that arises in a wide range of imaging modalities, from electron microscopy to Fourier ptychography. In particular, the reconstruction is facilitated when the sensing matrix is i.i.d. random, enabling strong theoretical guarantees and efficient reconstruction algorithms. However, its applicability is restricted by excessive computational costs. In this paper, we propose structured random models for phase retrieval, where we emulate a dense random matrix by a cascade of structured transforms and random diagonal matrices. We reduce the complexity from quadratic to log-linear at no cost in reconstruction performance. Through a spectral method initialization followed by gradient descent, robust reconstruction is obtained at an oversampling ratio as low as 2.8. Moreover, we observe that the reconstruction performance is solely determined by the singular-value distribution of the forward matrix. This class of models can directly be implemented with basic optical elements such as lenses and diffusers, paving the way for large-scale phase imaging with robust reconstruction guarantees.
-
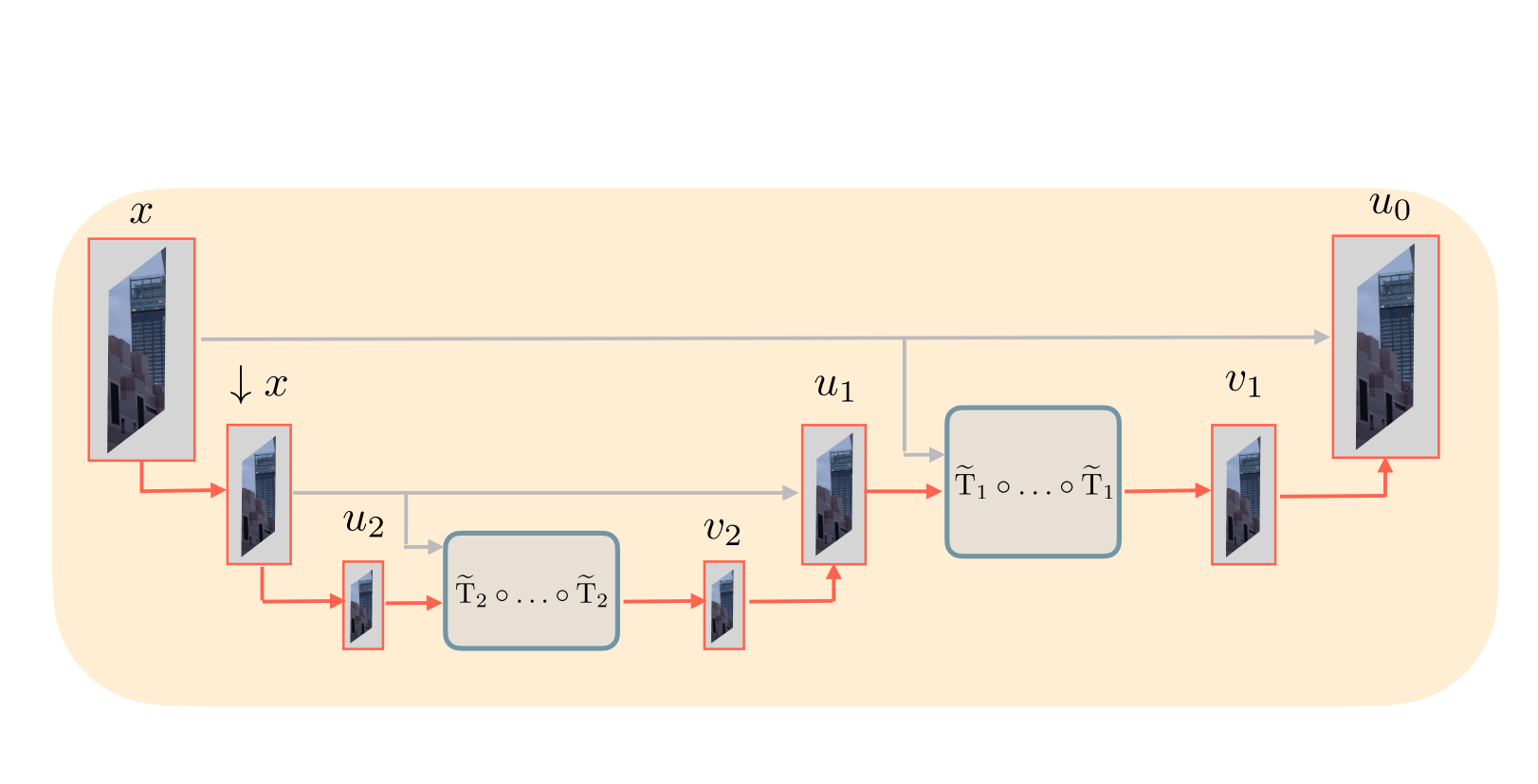 Multilevel Plug-and-Play Image RestorationNils Laurent , Julian Tachella, Elisa Riccietti , and Nelly PustelnikIEEE Transactions on Computational Imaging, 2025
Multilevel Plug-and-Play Image RestorationNils Laurent , Julian Tachella, Elisa Riccietti , and Nelly PustelnikIEEE Transactions on Computational Imaging, 2025Plug-and-play (PnP) image reconstruction methods leverage pretrained deep neural network denoisers as image priors to solve general inverse problems, and can obtain a competitive performance without having to train a network on a specific problem. Despite their flexibility, PnP methods often require several iterations to converge and their performance can be highly sensitive to the choice of the initialization and of the hyperparameters. In this paper, we propose a new multilevel PnP framework that accelerates the convergence by combining iterations at different scales, and improves the robustness to initialization and hyperparameters setting using a coarseto-fine strategy. In a series of experiments, including image inpainting and demosaicing, we show that the proposed multilevel PnP method outperforms other PnP methods in both speed and reconstruction performance.
-
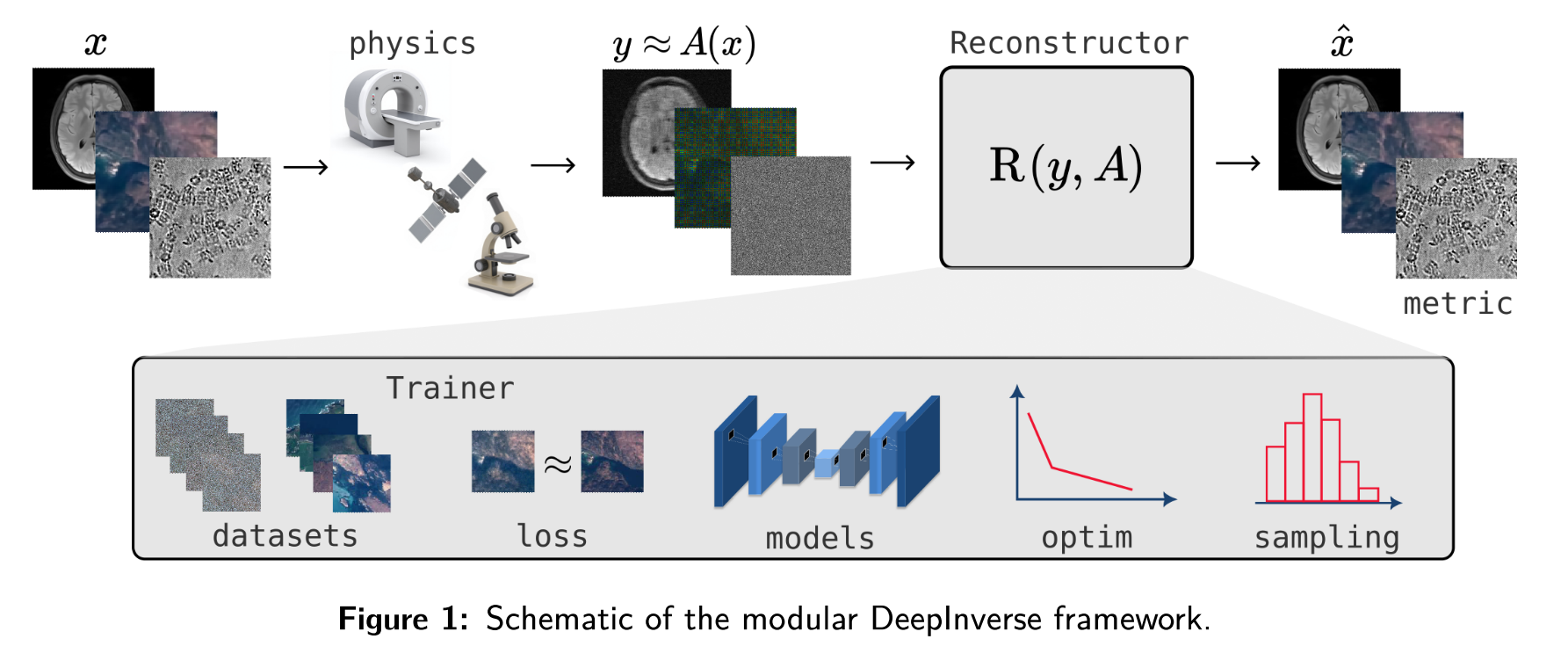 DeepInverse: A Python package for solving imaging inverse problems with deep learningJulian Tachella, Matthieu Terris , Samuel Hurault , Andrew Wang , Leo Davy , Jérémy Scanvic , Victor Sechaud , Romain Vo , Thomas Moreau , Thomas Davies , Dongdong Chen , Nils Laurent , Brayan Monroy , Jonathan Dong , Zhiyuan Hu , Minh-Hai Nguyen , Florian Sarron , Pierre Weiss , Paul Escande , Mathurin Massias , Thibaut Modrzyk , Brett Levac , Tobías I. Liaudat , Maxime Song , Johannes Hertrich , Sebastian Neumayer , and Georg SchrammJournal of Open Source Software, 2025
DeepInverse: A Python package for solving imaging inverse problems with deep learningJulian Tachella, Matthieu Terris , Samuel Hurault , Andrew Wang , Leo Davy , Jérémy Scanvic , Victor Sechaud , Romain Vo , Thomas Moreau , Thomas Davies , Dongdong Chen , Nils Laurent , Brayan Monroy , Jonathan Dong , Zhiyuan Hu , Minh-Hai Nguyen , Florian Sarron , Pierre Weiss , Paul Escande , Mathurin Massias , Thibaut Modrzyk , Brett Levac , Tobías I. Liaudat , Maxime Song , Johannes Hertrich , Sebastian Neumayer , and Georg SchrammJournal of Open Source Software, 2025 -
 Normalization-equivariant Diffusion Models: Learning Posterior Samplers From Noisy And Partial MeasurementsBrett Levac , Jon Tamir , Marcelo Pereyra , and Julian Tachella2025
Normalization-equivariant Diffusion Models: Learning Posterior Samplers From Noisy And Partial MeasurementsBrett Levac , Jon Tamir , Marcelo Pereyra , and Julian Tachella2025Diffusion models (DMs) have rapidly emerged as a powerful framework for image generation and restoration. However, existing DMs are primarily trained in a supervised manner by using a large corpus of clean images. This reliance on clean data poses fundamental challenges in many real-world scenarios, where acquiring noise-free data is hard or infeasible, and only noisy and potentially incomplete measurements are available. While some methods can train DMs using noisy data, they are generally effective only when the amount of noise is very mild or when some additional noise-free data is available. In addition, existing methods for training DMs from incomplete measurements require access to multiple complementary acquisition processes, an assumption that poses a significant practical limitation. Here we introduce the first approach for learning DMs for image restoration using only noisy measurement data from a single operator. As a first key contribution, we show that DMs, and more broadly minimum mean squared error denoisers, exhibit a weak form of scale equivariance linking rescaling in signal amplitude to changes in noise intensity. We then leverage this theoretical insight to develop a denoising score-matching strategy that generalizes robustly to noise levels lower than those present in the training data, thereby enabling the learning of DMs from noisy measurements. To further address the challenges of incomplete and noisy data, we integrate our method with equivariant imaging, a complementary self-supervised learning framework that exploits the inherent invariants of imaging problems, to train DMs for image restoration from single-operator measurements that are both incomplete and noisy. We validate the effectiveness of our approach through extensive experiments on image denoising, demosaicing, and inpainting, along with comparisons with the state of the art.
-
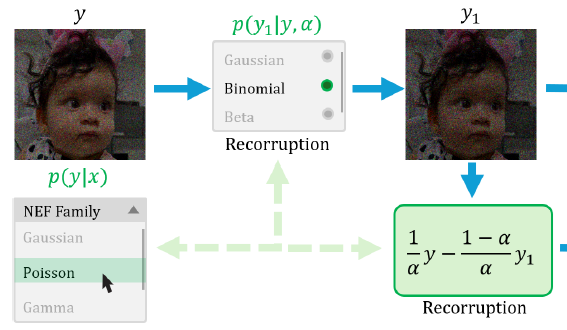 Generalized Recorrupted-to-Recorrupted: Self-Supervised Learning Beyond Gaussian NoiseBrayan Monroy , Jorge Bacca , and Julian TachellaCVPR 2025, 2025
Generalized Recorrupted-to-Recorrupted: Self-Supervised Learning Beyond Gaussian NoiseBrayan Monroy , Jorge Bacca , and Julian TachellaCVPR 2025, 2025Recorrupted-to-Recorrupted (R2R) has emerged as a methodology for training deep networks for image restoration in a self-supervised manner from noisy measurement data alone, demonstrating equivalence in expectation to the supervised squared loss in the case of Gaussian noise. However, its effectiveness with non-Gaussian noise remains unexplored. In this paper, we propose Generalized R2R (GR2R), extending the R2R framework to handle a broader class of noise distribution as additive noise like log-Rayleigh and address the natural exponential family including Poisson and Gamma noise distributions, which play a key role in many applications including low-photon imaging and synthetic aperture radar. We show that the GR2R loss is an unbiased estimator of the supervised loss and that the popular Stein’s unbiased risk estimator can be seen as a special case. A series of experiments with Gaussian, Poisson, and Gamma noise validate GR2R’s performance, showing its effectiveness compared to other self-supervised methods.
-
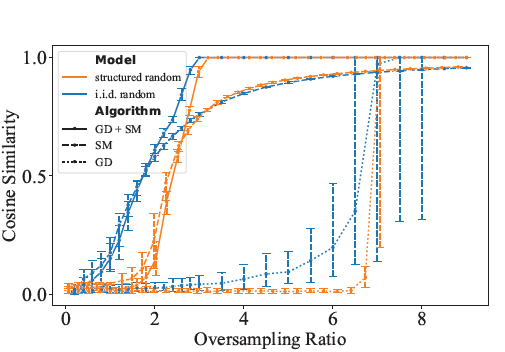 Structured Random Model for Fast and Robust Phase RetrievalZhiyuan Hu , Julian Tachella, Michael Unser , and Jonathan DongICASSP 2025, 2025
Structured Random Model for Fast and Robust Phase RetrievalZhiyuan Hu , Julian Tachella, Michael Unser , and Jonathan DongICASSP 2025, 2025Phase retrieval, a nonlinear problem prevalent in imaging applications, has been extensively studied using random models, some of which with i.i.d. sensing matrix components. While these models offer robust reconstruction guarantees, they are computationally expensive and impractical for real-world scenarios. In contrast, Fourier-based models, common in applications such as ptychography and coded diffraction imaging, are computationally more efficient but lack the theoretical guarantees of random models. Here, we introduce structured random models for phase retrieval that combine the efficiency of fast Fourier transforms with the versatility of random diagonal matrices. These models emulate i.i.d. random matrices at a fraction of the computational cost. Our approach demonstrates robust reconstructions comparable to fully random models using gradient descent and spectral methods. Furthermore, we establish that a minimum of two structured layers is necessary to achieve these structured-random properties. The proposed method is suitable for optical implementation and offers an efficient and robust alternative for phase retrieval in practical imaging applications.
-
 UNSURE: self-supervised learning with Unknown Noise level and Stein’s Unbiased Risk EstimateJulian Tachella, Mike Davies , and Laurent JacquesICLR 2025, 2025
UNSURE: self-supervised learning with Unknown Noise level and Stein’s Unbiased Risk EstimateJulian Tachella, Mike Davies , and Laurent JacquesICLR 2025, 2025Recently, many self-supervised learning methods for image reconstruction have been proposed that can learn from noisy data alone, bypassing the need for ground-truth references. Most existing methods cluster around two classes: i) Noise2Self and similar cross-validation methods that require very mild knowledge about the noise distribution, and ii) Stein’s Unbiased Risk Estimator (SURE) and similar approaches that assume full knowledge of the distribution. The first class of methods is often suboptimal compared to supervised learning, and the second class is often impractical, as the noise level is generally unknown in real-world applications. In this paper, we provide a theoretical framework that characterizes this expressivity-robustness trade-off and propose a new approach based on SURE, but unlike the standard SURE, does not require knowledge about the noise level. Throughout a series of experiments, we show that the proposed estimator outperforms other existing self-supervised methods on various imaging inverse problems.







2024
2024
-
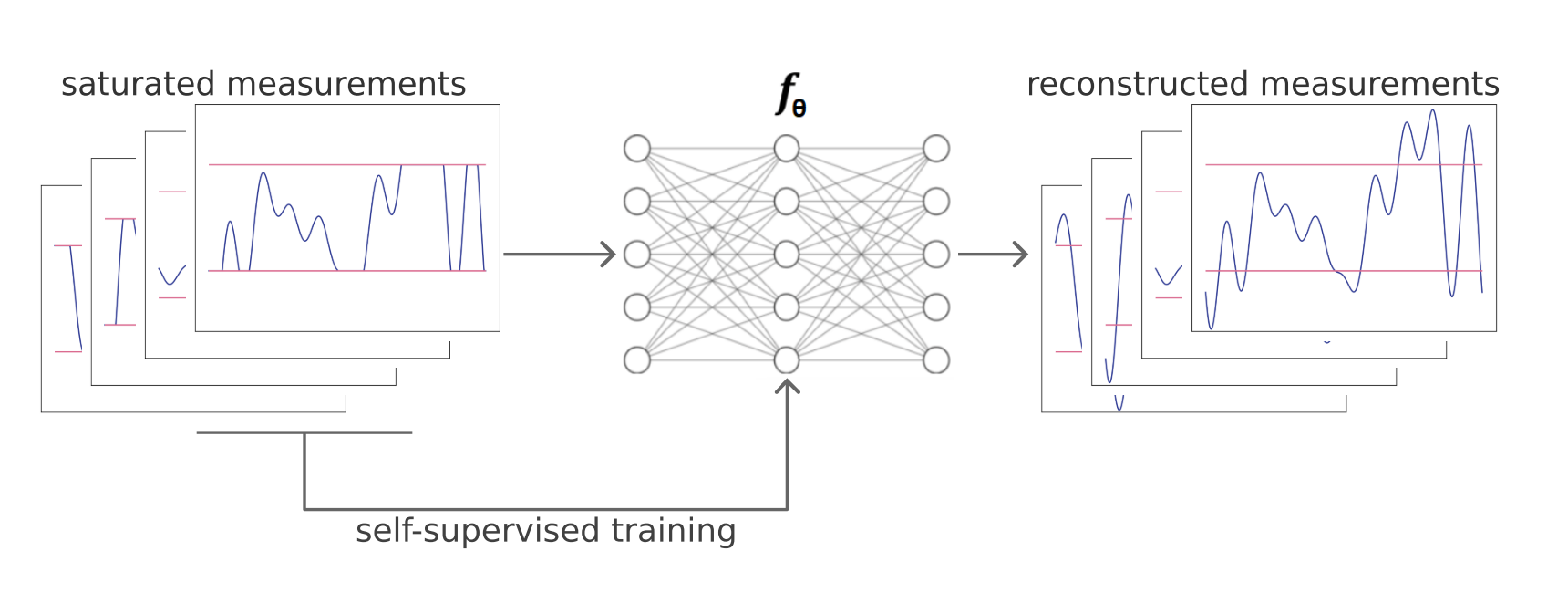 Equivariance-based self-supervised learning for audio signal recovery from clipped measurementsVictor Sechaud , Laurent Jacques , Patrice Abry , and Julian TachellaEUSIPCO 2024, 2024
Equivariance-based self-supervised learning for audio signal recovery from clipped measurementsVictor Sechaud , Laurent Jacques , Patrice Abry , and Julian TachellaEUSIPCO 2024, 2024In numerous inverse problems, state-of-the-art solving strategies involve training neural networks from ground truth and associated measurement datasets that, however, may be expensive or impossible to collect. Recently, self-supervised learning techniques have emerged, with the major advantage of no longer requiring ground truth data. Most theoretical and experimental results on self-supervised learning focus on linear inverse problems. The present work aims to study self-supervised learning for the non-linear inverse problem of recovering audio signals from clipped measurements. An equivariance-based selfsupervised loss is proposed and studied. Performance is assessed on simulated clipped measurements with controlled and varied levels of clipping, and further reported on standard real music signals. We show that the performance of the proposed equivariance-based self-supervised declipping strategy compares favorably to fully supervised learning while only requiring clipped measurements alone for training.
-
 Equivariant plug-and-play image reconstructionMatthieu Terris , Thomas Moreau , Nelly Pustelnik , and Julian TachellaCVPR’24, 2024
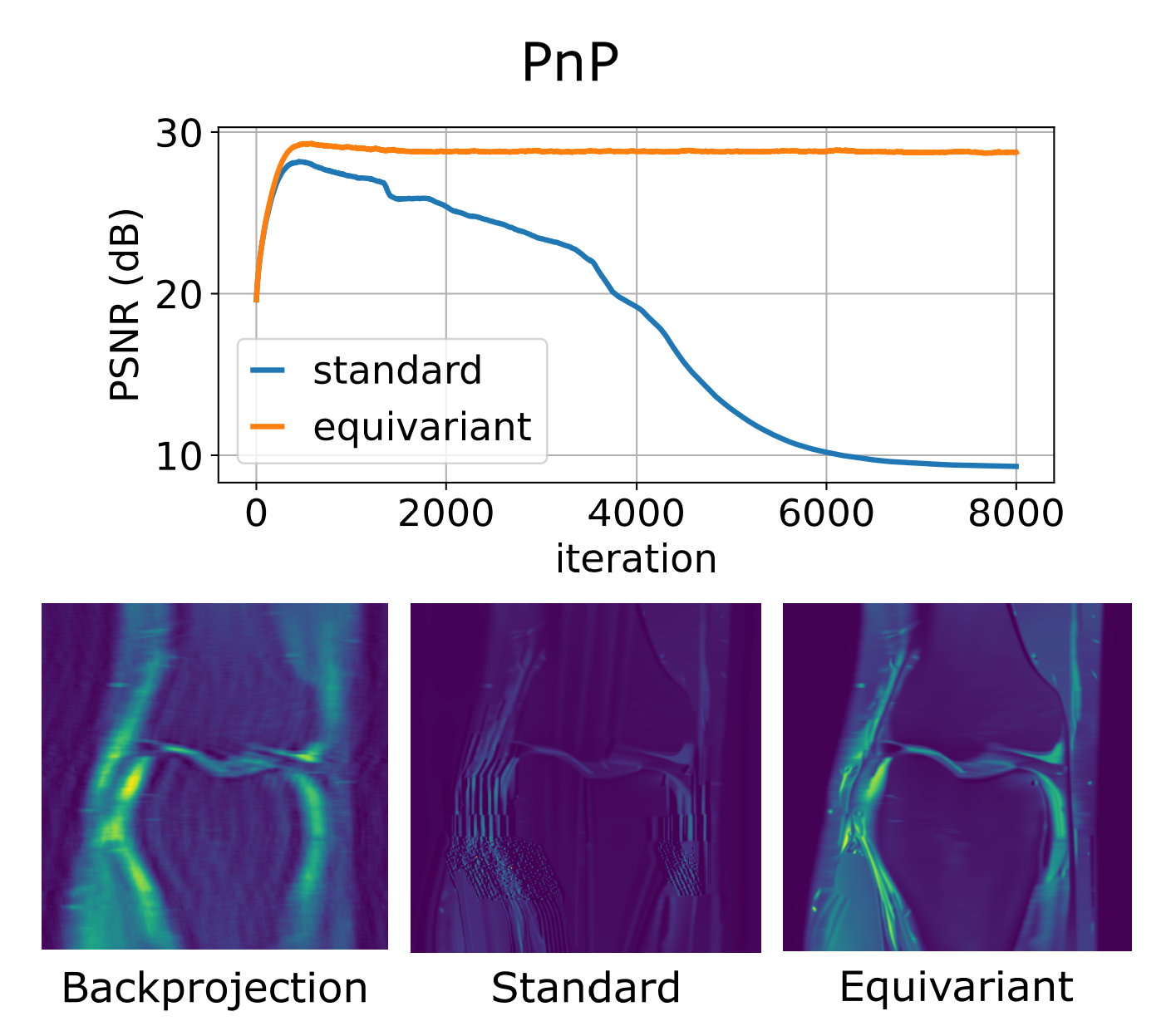
Equivariant plug-and-play image reconstructionMatthieu Terris , Thomas Moreau , Nelly Pustelnik , and Julian TachellaCVPR’24, 2024Plug-and-play algorithms constitute a popular framework for solving inverse imaging problems that rely on the implicit definition of an image prior via a denoiser. These algorithms can leverage powerful pre-trained denoisers to solve a wide range of imaging tasks, circumventing the necessity to train models on a per-task basis. Unfortunately, plug-and-play methods often show unstable behaviors, hampering their promise of versatility and leading to suboptimal quality of reconstructed images. In this work, we show that enforcing equivariance to certain groups of transformations (rotations, reflections, and/or translations) on the denoiser strongly improves the stability of the algorithm as well as its reconstruction quality. We provide a theoretical analysis that illustrates the role of equivariance on better performance and stability. We present a simple algorithm that enforces equivariance on any existing denoiser by simply applying a random transformation to the input of the denoiser and the inverse transformation to the output at each iteration of the algorithm. Experiments on multiple imaging modalities and denoising networks show that the equivariant plug-and-play algorithm improves both the reconstruction performance and the stability compared to their non-equivariant counterparts.
-
 Equivariant Bootstrapping for Uncertainty Quantification in Imaging Inverse ProblemsJulian Tachella, and Marcelo PereyraAISTATS 2024, Oral Presentation, 2024
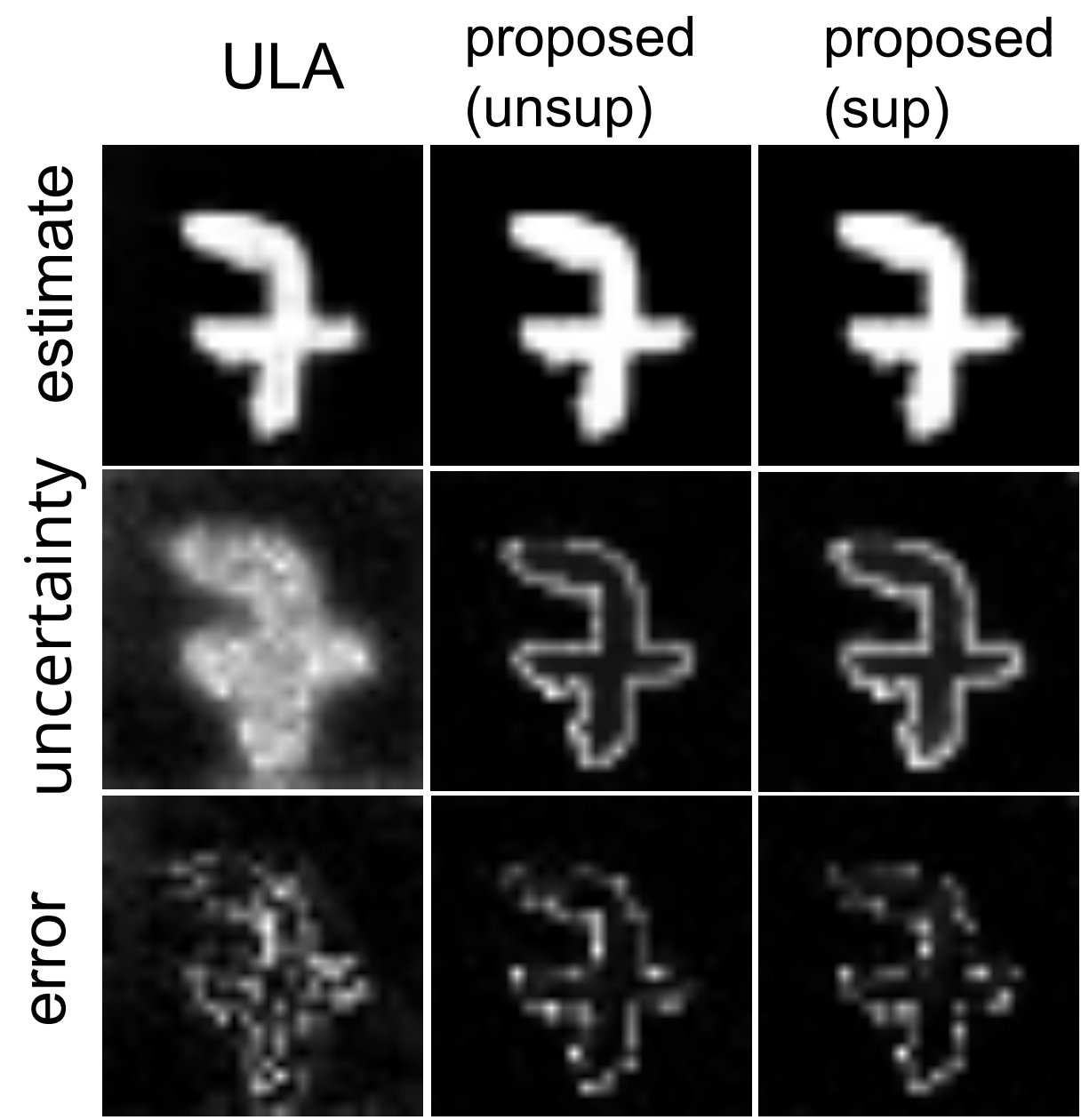
Equivariant Bootstrapping for Uncertainty Quantification in Imaging Inverse ProblemsJulian Tachella, and Marcelo PereyraAISTATS 2024, Oral Presentation, 2024Scientific imaging problems are often severely ill-posed, and hence have significant intrinsic uncertainty. Accurately quantifying the uncertainty in the solutions to such problems is therefore critical for the rigorous interpretation of experimental results as well as for reliably using the reconstructed images as scientific evidence. Unfortunately, existing imaging methods are unable to quantify the uncertainty in the reconstructed images in a manner that is robust to experiment replications. This paper presents a new uncertainty quantification methodology based on an equivariant formulation of the parametric bootstrap algorithm that leverages symmetries and invariance properties commonly encountered in imaging problems. Additionally, the proposed methodology is general and can be easily applied with any image reconstruction technique, including unsupervised training strategies that can be trained from observed data alone, thus enabling uncertainty quantification in situations where there is no ground truth data available. We demonstrate the proposed approach with a series of numerical experiments and through comparisons with alternative uncertainty quantification strategies from the state-of-the-art, such as Bayesian strategies involving score-based diffusion models and Langevin samplers. In all our experiments, the proposed method delivers remarkably accurate high-dimensional confidence regions and outperforms the competing approaches in terms of estimation accuracy, uncertainty quantification accuracy, and computing time.
-
 Spline Sketches: An Efficient Approach for Photon Counting LidarMichael P Sheehan , Julian Tachella, and Mike E DaviesIEEE Transactions on Computational Imaging, 2024
Spline Sketches: An Efficient Approach for Photon Counting LidarMichael P Sheehan , Julian Tachella, and Mike E DaviesIEEE Transactions on Computational Imaging, 2024Photon counting lidar has become an invaluable tool for 3D depth imaging due to the fine-precision it can achieve over long ranges. However, high frame rate, high resolution lidar devices produce an enormous amount of time-of-flight (ToF) data which can cause a severe data processing bottleneck hindering the deployment of real-time systems. In this paper, an efficient photon counting approach is proposed that exploits the simplicity of piecewise polynomial splines to form a hardware-friendly compressed statistic, or a so-called spline sketch, of the ToF data without sacrificing the quality of the recovered image. As each piecewise polynomial spline is a simple function with limited support over the timing depth window, the spline sketch can be computed efficiently on-chip with minimal computational overhead. We show that a piecewise linear or quadratic spline sketch, requiring minimal on-chip arithmetic computation per photon detection, can reconstruct real-world depth images with negligible loss of resolution whilst achieving 95% compression compared to the full ToF data, as well as offering multi-peak detection performance. These contrast with previously proposed coarse binning histograms that suffer from a highly nonuniform accuracy across depth and can fail catastrophically when associated with bright reflectors. Further, by building range-walk correction into the proposed estimation algorithms, it is demonstrated that the spline sketches can be made robust to photon pile-up effects. The computational complexity of both the reconstruction and range walk correction algorithms scale only with the size of the spline sketch which is independent to both the photon count and temporal resolution of the lidar device.




2023
2023
-
 Self-Supervised Learning for Image Super-Resolution and DeblurringJeremy Scanvic , Mike Davies , Patrice Abry , and Julian TachellaarXiv preprint arXiv:2312.11232, 2023
Self-Supervised Learning for Image Super-Resolution and DeblurringJeremy Scanvic , Mike Davies , Patrice Abry , and Julian TachellaarXiv preprint arXiv:2312.11232, 2023Self-supervised methods have recently proved to be nearly as effective as supervised methods in various imaging inverse problems, paving the way for learning-based methods in scientific and medical imaging applications where ground truth data is hard or expensive to obtain. This is the case in magnetic resonance imaging and computed tomography. These methods critically rely on invariance to translations and/or rotations of the image distribution to learn from incomplete measurement data alone. However, existing approaches fail to obtain competitive performances in the problems of image super-resolution and deblurring, which play a key role in most imaging systems. In this work, we show that invariance to translations and rotations is insufficient to learn from measurements that only contain low-frequency information. Instead, we propose a new self-supervised approach that leverages the fact that many image distributions are approximately scale-invariant, and that can be applied to any inverse problem where high-frequency information is lost in the measurement process. We demonstrate throughout a series of experiments on real datasets that the proposed method outperforms other self-supervised approaches, and obtains performances on par with fully supervised learning.
-
 Learning to Reconstruct Signals from Binary MeasurementsJulian Tachella, and Laurent JacquesTransactions of Machine Learning Research (TMLR). Featured Certification., 2023
Learning to Reconstruct Signals from Binary MeasurementsJulian Tachella, and Laurent JacquesTransactions of Machine Learning Research (TMLR). Featured Certification., 2023Recent advances in unsupervised learning have highlighted the possibility of learning to reconstruct signals from noisy and incomplete linear measurements alone. These methods play a key role in medical and scientific imaging and sensing, where ground truth data is often scarce or difficult to obtain. However, in practice, measurements are not only noisy and incomplete but also quantized. Here we explore the extreme case of learning from binary observations and provide necessary and sufficient conditions on the number of measurements required for identifying a set of signals from incomplete binary data. Our results are complementary to existing bounds on signal recovery from binary measurements. Furthermore, we introduce a novel self-supervised learning approach, which we name SSBM, that only requires binary data for training. We demonstrate in a series of experiments with real datasets that SSBM performs on par with supervised learning and outperforms sparse reconstruction methods with a fixed wavelet basis by a large margin.
- Hardware Friendly Spline Sketched LidarMichael P Sheehan , Julian Tachella, and Mike E DaviesIn ICASSP’23 , 2023
Photon counting lidar has become an invaluable tool for 3D depth imaging due to the fine-precision it can achieve over long ranges. However, high frame rate, high resolution lidar devices produce an enormous amount of time-of-flight (ToF) data which can cause a severe data processing bottleneck hindering the deployment of real-time systems. In this paper, an efficient photon counting approach is proposed that exploits the simplicity of piecewise polynomial splines to form a hardware-friendly compressed statistic, or a so-called spline sketch, of the ToF data without sacrificing the quality of the recovered image. As each piecewise polynomial spline is a simple function with limited support over the timing depth window, the spline sketch can be computed efficiently on-chip with minimal computational overhead. We show that a piecewise linear or quadratic spline sketch, requiring minimal on-chip arithmetic computation per photon detection, can reconstruct real-world depth images with negligible loss of resolution whilst achieving 95% compression compared to the full ToF data, as well as offering multi-peak detection performance. These contrast with previously proposed coarse binning histograms that suffer from a highly nonuniform accuracy across depth and can fail catastrophically when associated with bright reflectors. Further, by building range-walk correction into the proposed estimation algorithms, it is demonstrated that the spline sketches can be made robust to photon pile-up effects. The computational complexity of both the reconstruction and range walk correction algorithms scale only with the size of the spline sketch which is independent to both the photon count and temporal resolution of the lidar device.
-
 Imaging with Equivariant Deep LearningDongdong Chen , Mike Davies , Matthias J Ehrhardt , Carola-Bibiane Schönlieb , Ferdia Sherry , and Julian TachellaIEEE Signal Processing Magazine, 2023
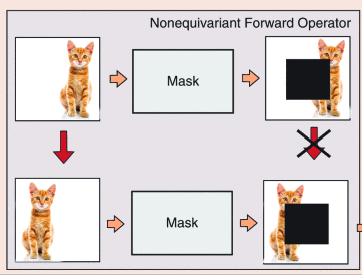
Imaging with Equivariant Deep LearningDongdong Chen , Mike Davies , Matthias J Ehrhardt , Carola-Bibiane Schönlieb , Ferdia Sherry , and Julian TachellaIEEE Signal Processing Magazine, 2023From early image processing to modern computational imaging, successful models and algorithms have relied on a fundamental property of natural signals: symmetry . Here symmetry refers to the invariance property of signal sets to transformations, such as translation, rotation, or scaling. Symmetry can also be incorporated into deep neural networks (DNNs) in the form of equivariance, allowing for more data-efficient learning. While there have been important advances in the design of end-to-end equivariant networks for image classification in recent years, computational imaging introduces unique challenges for equivariant network solutions since we typically only observe the image through some noisy ill-conditioned forward operator that itself may not be equivariant. We review the emerging field of equivariant imaging (EI) and show how it can provide improved generalization and new imaging opportunities. Along the way, we show the interplay between the acquisition physics and group actions and links to iterative reconstruction, blind compressed sensing, and self-supervised learning.
-
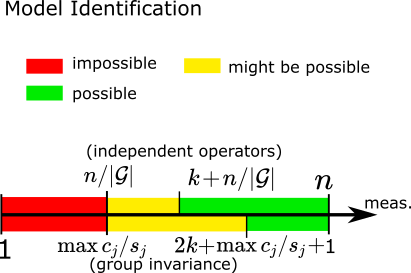 Sensing Theorems for Unsupervised Learning in Linear Inverse ProblemsJulian Tachella, Dongdong Chen , and Mike DaviesJournal of Machine Learning Research (JMLR), Jan 2023
Sensing Theorems for Unsupervised Learning in Linear Inverse ProblemsJulian Tachella, Dongdong Chen , and Mike DaviesJournal of Machine Learning Research (JMLR), Jan 2023Solving a linear inverse problem requires knowledge about the underlying signal model. In many applications, this model is a priori unknown and has to be learned from data. However, it is impossible to learn the model using observations obtained via a single incomplete measurement operator, as there is no information outside the range of the inverse operator, resulting in a chicken-and-egg problem: to learn the model we need reconstructed signals, but to reconstruct the signals we need to know the model. Two ways to overcome this limitation are using multiple measurement operators or assuming that the signal model is invariant to a certain group action. In this paper, we present necessary and sufficient sensing conditions for learning the signal model from partial measurements which only depend on the dimension of the model, and the number of operators or properties of the group action that the model is invariant to. As our results are agnostic of the learning algorithm, they shed light into the fundamental limitations of learning from incomplete data and have implications in a wide range set of practical algorithms, such as dictionary learning, matrix completion and deep neural networks.




2022
2022
-
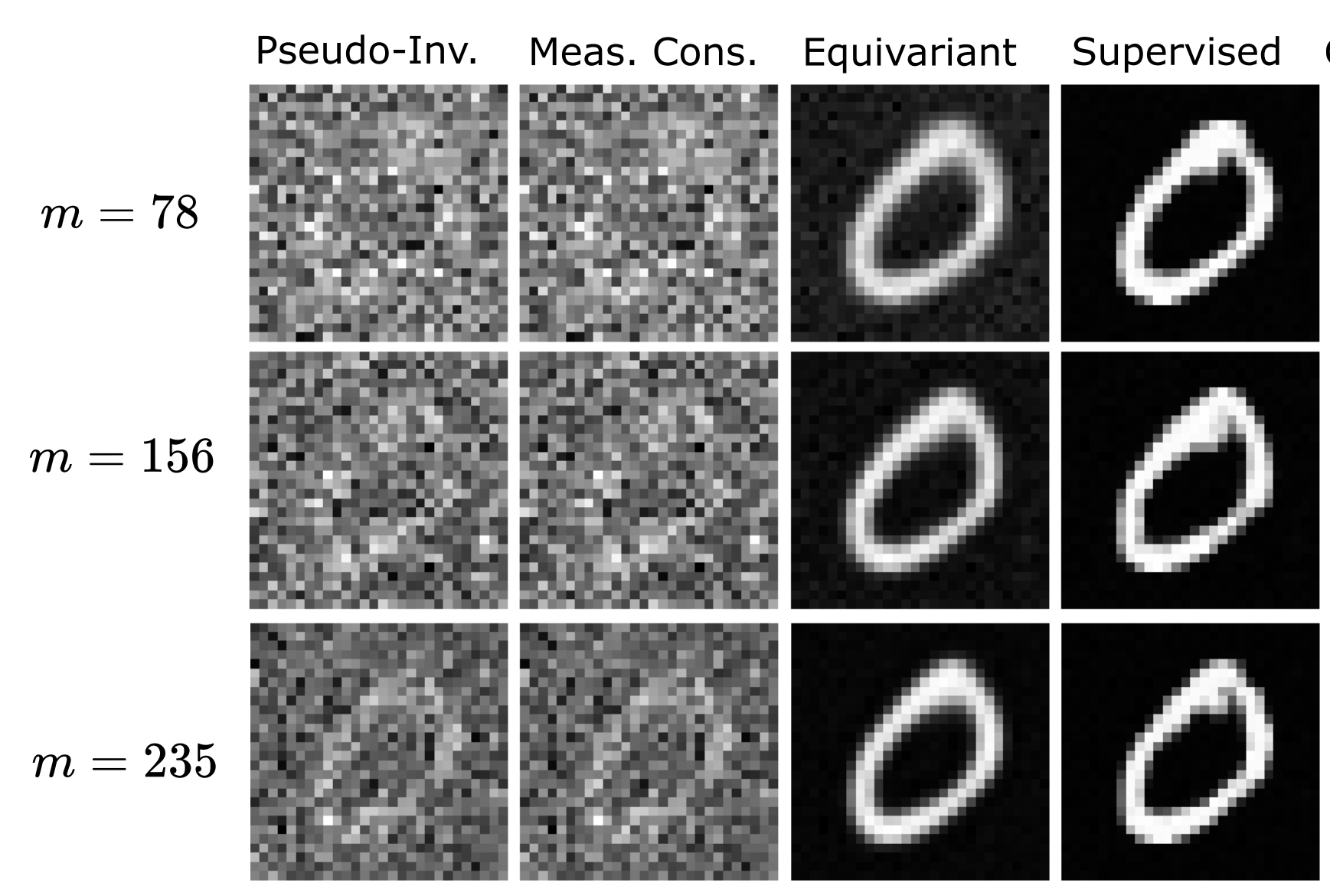 Unsupervised Learning to Solve Inverse Problems: Application to Single-Pixel ImagingJulian Tachella, Dongdong Chen , and Mike DaviesGRETSI’22, Sep 2022
Unsupervised Learning to Solve Inverse Problems: Application to Single-Pixel ImagingJulian Tachella, Dongdong Chen , and Mike DaviesGRETSI’22, Sep 2022In recent years, learning-based approaches have obtained state-of-the-art performance in multiple imaging inverse problems ranging from medical imaging to computational photography. These methods generally require pairs of signals and associated measurements for training. However, in various imaging problems, we usually only have access to compressed measurements of the underlying signals, hindering this learning-based approach. Learning from measurement data only is impossible in general, as the compressed observations do not contain information in the nullspace of the forward sensing operator. The recent equivariant imaging framework overcomes this limitation by exploiting the invariance to transformations (translations, rotations, etc.) present in natural signals. In this paper, we leverage this novel unsupervised learning framework for reconstructing single-pixel imaging data from compressed measurements alone. A series of experiments show that the proposed method performs comparably to the standard supervised approach.
-
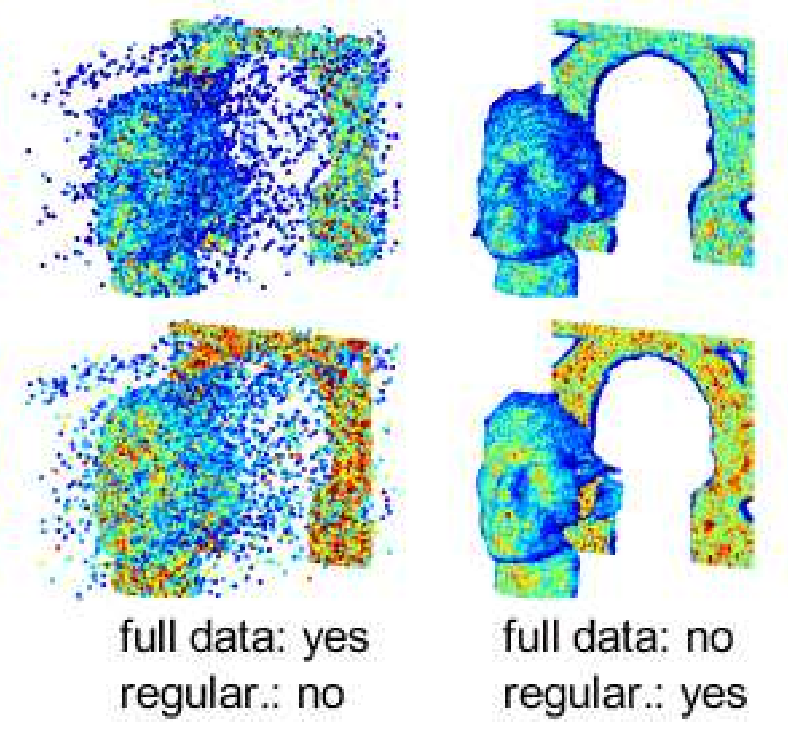 Sketched RT3D: How to reconstruct billions of photons per secondJulian Tachella, Michael P. Sheehan , and Mike DaviesBest Student Paper Award at ICASSP’22, Mar 2022
Sketched RT3D: How to reconstruct billions of photons per secondJulian Tachella, Michael P. Sheehan , and Mike DaviesBest Student Paper Award at ICASSP’22, Mar 2022Single-photon light detection and ranging (lidar) captures depth and intensity information of a 3D scene. Reconstructing a scene from observed photons is a challenging task due to spurious detections associated with background illumination sources. To tackle this problem, there is a plethora of 3D reconstruction algorithms which exploit spatial regularity of natural scenes to provide stable reconstructions. However, most existing algorithms have computational and memory complexity proportional to the number of recorded photons. This complexity hinders their real-time deployment on modern lidar arrays which acquire billions of photons per second. Leveraging a recent lidar sketching framework, we show that it is possible to modify existing reconstruction algorithms such that they only require a small sketch of the photon information. In particular, we propose a sketched version of a recent state-of-the-art algorithm which uses point cloud denoisers to provide spatially regularized reconstructions. A series of experiments performed on real lidar datasets demonstrates a significant reduction of execution time and memory requirements, while achieving the same reconstruction performance than in the full data case.
-
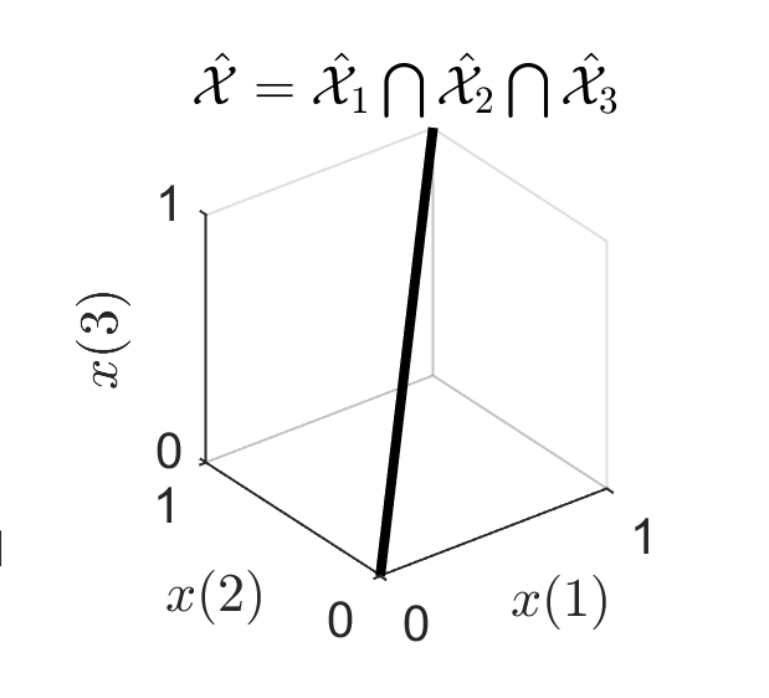 Unsupervised Learning From Incomplete Measurements for Inverse ProblemsJulian Tachella, Dongdong Chen , and Mike DaviesNeurIPS 2022, May 2022
Unsupervised Learning From Incomplete Measurements for Inverse ProblemsJulian Tachella, Dongdong Chen , and Mike DaviesNeurIPS 2022, May 2022In many real-world inverse problems, only incomplete measurement data are available for training which can pose a problem for learning a reconstruction function. Indeed, unsupervised learning using a fixed incomplete measurement process is impossible in general, as there is no information in the nullspace of the measurement operator. This limitation can be overcome by using measurements from multiple operators. While this idea has been successfully applied in various applications, a precise characterization of the conditions for learning is still lacking. In this paper, we fill this gap by presenting necessary and sufficient conditions for learning the underlying signal model needed for reconstruction which indicate the interplay between the number of distinct measurement operators, the number of measurements per operator, the dimension of the model and the dimension of the signals. Furthermore, we propose a novel and conceptually simple unsupervised learning loss which only requires access to incomplete measurement data and achieves a performance on par with supervised learning when the sufficient condition is verified. We validate our theoretical bounds and demonstrate the advantages of the proposed unsupervised loss compared to previous methods via a series of experiments on various imaging inverse problems, such as accelerated magnetic resonance imaging, compressed sensing and image inpainting.
-
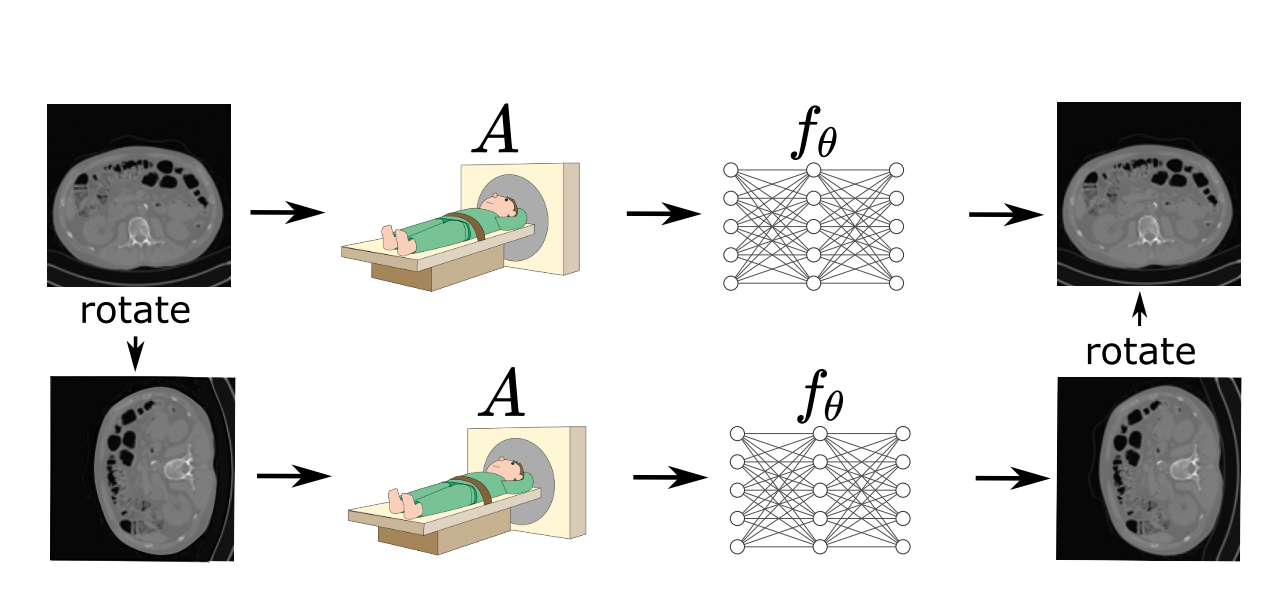 Robust Equivariant Imaging: a fully unsupervised framework for learning to image from noisy and partial measurementsDongdong Chen , Julian Tachella, and Mike E DaviesProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022
Robust Equivariant Imaging: a fully unsupervised framework for learning to image from noisy and partial measurementsDongdong Chen , Julian Tachella, and Mike E DaviesProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022Deep networks provide state-of-the-art performance in multiple imaging inverse problems ranging from medical imaging to computational photography. However, most existing networks are trained with clean signals which are often hard or impossible to obtain. Equivariant imaging (EI) is a recent self-supervised learning framework that exploits the group invariance present in signal distributions to learn a reconstruction function from partial measurement data alone. While EI results are impressive, its performance degrades with increasing noise. In this paper, we propose a Robust Equivariant Imaging (REI) framework which can learn to image from noisy partial measurements alone. The proposed method uses Stein’s Unbiased Risk Estimator (SURE) to obtain a fully unsupervised training loss that is robust to noise. We show that REI leads to considerable performance gains on linear and nonlinear inverse problems, thereby paving the way for robust unsupervised imaging with deep networks.



2021
2021
-
 Surface Detection for Sketched Single Photon LidarMichael P. Sheehan , Julian Tachella, and Mike E. DaviesIn 2021 29th European Signal Processing Conference (EUSIPCO) , Aug 2021
Surface Detection for Sketched Single Photon LidarMichael P. Sheehan , Julian Tachella, and Mike E. DaviesIn 2021 29th European Signal Processing Conference (EUSIPCO) , Aug 2021Single-photon lidar devices are able to collect an ever-increasing amount of time-stamped photons in small time periods due to increasingly larger arrays, generating a memory and computational bottleneck on the data processing side. Recently, a sketching technique was introduced to overcome this bottleneck which compresses the amount of information to be stored and processed. The size of the sketch scales with the number of underlying parameters of the time delay distribution and not, fundamentally, with either the number of detected photons or the time-stamp resolution. In this paper, we propose a detection algorithm based solely on a small sketch that determines if there are surfaces or objects in the scene or not. If a surface is detected, the depth and intensity of a single object can be computed in closed-form directly from the sketch. The computational load of the proposed detection algorithm depends solely on the size of the sketch, in contrast to previous algorithms that depend at least linearly in the number of collected photons or histogram bins, paving the way for fast, accurate and memory efficient lidar estimation. Our experiments demonstrate the memory and statistical efficiency of the proposed algorithm both on synthetic and real lidar datasets.
-
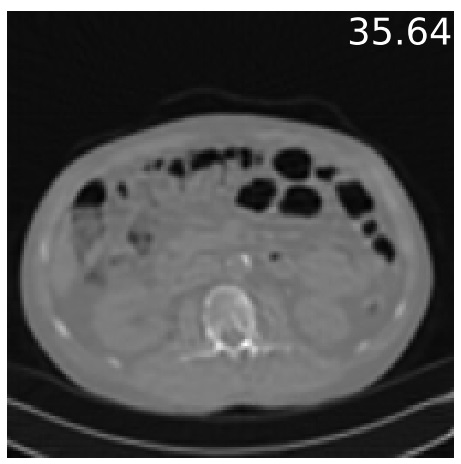 Equivariant Imaging: Learning Beyond the Range SpaceDongdong Chen , Julian Tachella, and Mike E DaviesIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , Mar 2021
Equivariant Imaging: Learning Beyond the Range SpaceDongdong Chen , Julian Tachella, and Mike E DaviesIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , Mar 2021In various imaging problems, we only have access to compressed measurements of the underlying signals, hindering most learning-based strategies which usually require pairs of signals and associated measurements for training. Learning only from compressed measurements is impossible in general, as the compressed observations do not contain information outside the range of the forward sensing operator. We propose a new end-to-end self-supervised framework that overcomes this limitation by exploiting the equivariances present in natural signals. Our proposed learning strategy performs as well as fully supervised methods. Experiments demonstrate the potential of this framework on inverse problems including sparse-view X-ray computed tomography on real clinical data and image inpainting on natural images.
-
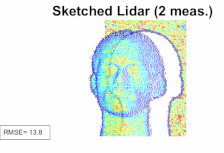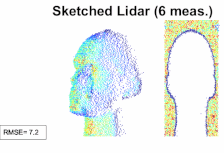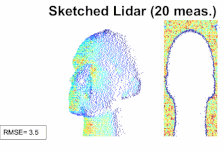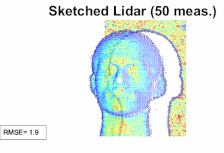 A sketching framework for reduced data transfer in photon counting lidarMichael P Sheehan , Julian Tachella, and Mike E DaviesIEEE Transactions on Computational Imaging, Mar 2021
A sketching framework for reduced data transfer in photon counting lidarMichael P Sheehan , Julian Tachella, and Mike E DaviesIEEE Transactions on Computational Imaging, Mar 2021Single-photon lidar has become a prominent tool for depth imaging in recent years. At the core of the technique, the depth of a target is measured by constructing a histogram of time delays between emitted light pulses and detected photon arrivals. A major data processing bottleneck arises on the device when either the number of photons per pixel is large or the resolution of the time-stamp is fine, as both the space requirement and the complexity of the image reconstruction algorithms scale with these parameters. We solve this limiting bottleneck of existing lidar techniques by sampling the characteristic function of the time of flight (ToF) model to build a compressive statistic, a so-called sketch of the time delay distribution, which is sufficient to infer the spatial distance and intensity of the object. The size of the sketch scales with the degrees of freedom of the ToF model (number of objects) and not, fundamentally, with the number of photons or the time-stamp resolution. Moreover, the sketch is highly amenable for on-chip online processing. We show theoretically that the loss of information for compression is controlled and the mean squared error of the inference quickly converges towards the optimal Cramér-Rao bound (i.e. no loss of information) for modest sketch sizes. The proposed compressed single-photon lidar framework is tested and evaluated on real life datasets of complex scenes where it is shown that a compression rate of up-to 150 is achievable in practice without sacrificing the overall resolution of the reconstructed image.
-
 The Neural Tangent Link Between CNN Denoisers and Non-Local FiltersJulian Tachella, Junqi Tang , and Mike DaviesIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2021
The Neural Tangent Link Between CNN Denoisers and Non-Local FiltersJulian Tachella, Junqi Tang , and Mike DaviesIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2021Convolutional Neural Networks (CNNs) are now a well-established tool for solving computational imaging problems. Modern CNN-based algorithms obtain state-of-the-art performance in diverse image restoration problems. Furthermore, it has been recently shown that, despite being highly overparameterized, networks trained with a single corrupted image can still perform as well as fully trained networks. We introduce a formal link between such networks through their neural tangent kernel (NTK), and well-known non-local filtering techniques, such as non-local means or BM3D. The filtering function associated with a given network architecture can be obtained in closed form without need to train the network, being fully characterized by the random initialization of the network weights. While the NTK theory accurately predicts the filter associated with networks trained using standard gradient descent, our analysis shows that it falls short to explain the behaviour of networks trained using the popular Adam optimizer. The latter achieves a larger change of weights in hidden layers, adapting the non-local filtering function during training. We evaluate our findings via extensive image denoising experiments.




2020
2020
-
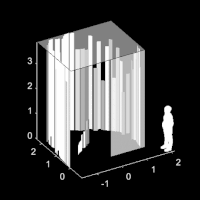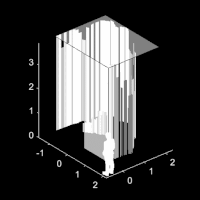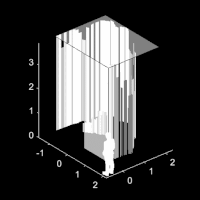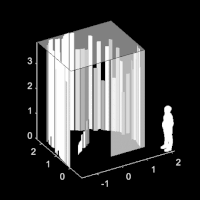 Seeing around corners with edge-resolved transient imagingJoshua Rapp , Charles Saunders , Julian Tachella, John Murray-Bruce , Yoann Altmann , Jean-Yves Tourneret , Stephen McLaughlin , Robin Dawson , Franco NC Wong , and Vivek K GoyalNature communications, Jun 2020
Seeing around corners with edge-resolved transient imagingJoshua Rapp , Charles Saunders , Julian Tachella, John Murray-Bruce , Yoann Altmann , Jean-Yves Tourneret , Stephen McLaughlin , Robin Dawson , Franco NC Wong , and Vivek K GoyalNature communications, Jun 2020Non-line-of-sight (NLOS) imaging is a rapidly growing field seeking to form images of objects outside the field of view, with potential applications in autonomous navigation, reconnaissance, and even medical imaging. The critical challenge of NLOS imaging is that diffuse reflections scatter light in all directions, resulting in weak signals and a loss of directional information. To address this problem, we propose a method for seeing around corners that derives angular resolution from vertical edges and longitudinal resolution from the temporal response to a pulsed light source. We introduce an acquisition strategy, scene response model, and reconstruction algorithm that enable the formation of 2.5-dimensional representations—a plan view plus heights—and a 180∘ field of view for large-scale scenes. Our experiments demonstrate accurate reconstructions of hidden rooms up to 3 meters in each dimension despite a small scan aperture (1.5-centimeter radius) and only 45 measurement locations.
-
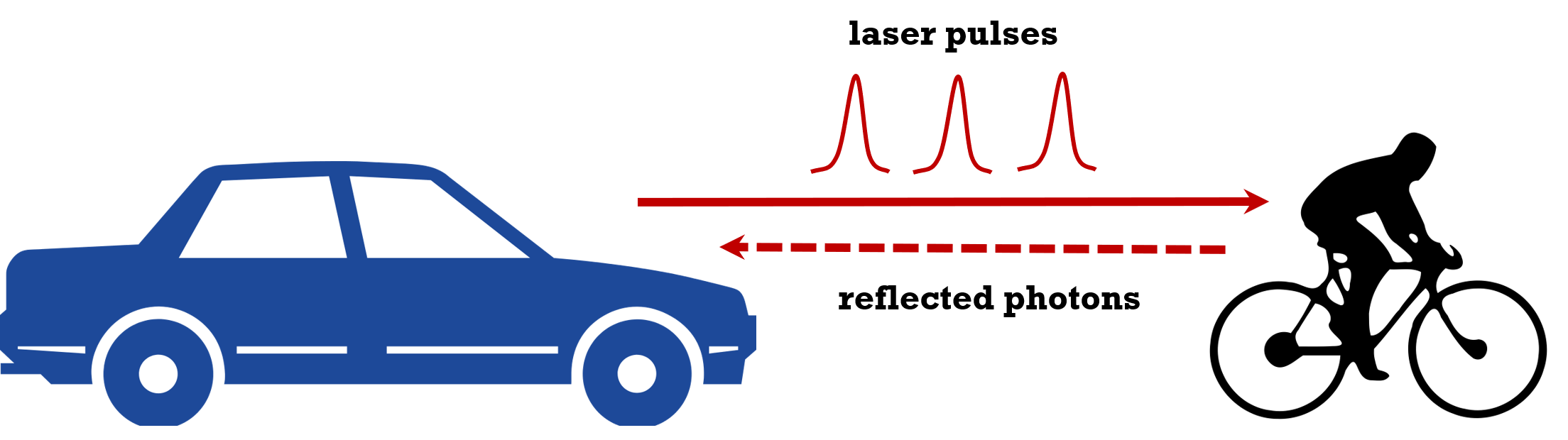 Advances in single-photon lidar for autonomous vehicles: Working principles, challenges, and recent advancesJoshua Rapp , Julian Tachella, Yoann Altmann , Stephen McLaughlin , and Vivek K GoyalIEEE Signal Processing Magazine, Jun 2020
Advances in single-photon lidar for autonomous vehicles: Working principles, challenges, and recent advancesJoshua Rapp , Julian Tachella, Yoann Altmann , Stephen McLaughlin , and Vivek K GoyalIEEE Signal Processing Magazine, Jun 2020The safety and success of autonomous vehicles (AVs) depend on their ability to accurately map and respond to their surroundings in real time. One of the most promising recent technologies for depth mapping is single-photon lidar (SPL), which measures the time of flight of individual photons. The long-range capabilities (kilometers), excellent depth resolution (centimeters), and use of low-power (eye-safe) laser sources renders this modality a strong candidate for use in AVs. While presenting unique opportunities, the remarkable sensitivity of single-photon detectors introduces several signal processing challenges. The discrete nature of photon counting and the particular design of the detection devices means the acquired signals cannot be treated as arising in a linear system with additive Gaussian noise. Moreover, the number of useful photon detections may be small despite a large data volume, thus requiring careful modeling and algorithmic design for real-time performance. This article discusses the main working principles of SPL and summarizes recent advances in signal processing techniques for this modality, highlighting promising applications in AVs as well as a number of challenges for vehicular lidar that cannot be solved by better hardware alone.


2019
2019
-
 Real-time 3D color imaging with single-photon lidar dataJulian Tachella, Yoann Altmann , Stephen McLaughlin , and Jean-Yves TourneretIn Proc. 8th Int. Workshop Comput. Adv. Multi-Sensor Adap. Process. (CAMSAP) , Dec 2019
Real-time 3D color imaging with single-photon lidar dataJulian Tachella, Yoann Altmann , Stephen McLaughlin , and Jean-Yves TourneretIn Proc. 8th Int. Workshop Comput. Adv. Multi-Sensor Adap. Process. (CAMSAP) , Dec 2019Single-photon lidar devices can acquire 3D data at very long range with high precision. Moreover, recent advances in lidar arrays have enabled acquisitions at very high frame rates. However, these devices place a severe bottleneck on the reconstruction algorithms, which have to handle very large volumes of noisy data. Recently, real-time 3D reconstruction of distributed surfaces has been demonstrated obtaining information at one wavelength. Here, we propose a new algorithm that achieves color 3D reconstruction without increasing the execution time nor the acquisition process of the realtime single-wavelength reconstruction system. The algorithm uses a coded aperture that compresses the data by considering a subset of the wavelengths per pixel. The reconstruction algorithm is based on a plug-and-play denoising framework, which benefits from off-the-shelf point cloud and image de-noisers. Experiments using real lidar data show the competitivity of the proposed method.
-
 Bayesian 3D Reconstruction of Subsampled Multispectral Single-photon Lidar SignalsJulian Tachella, Yoann Altmann , Miguel Márquez , Henry Arguello-Fuentes , Jean-Yves Tourneret , and Stephen McLaughlinIEEE Trans. Comput. Imag., Apr 2019
Bayesian 3D Reconstruction of Subsampled Multispectral Single-photon Lidar SignalsJulian Tachella, Yoann Altmann , Miguel Márquez , Henry Arguello-Fuentes , Jean-Yves Tourneret , and Stephen McLaughlinIEEE Trans. Comput. Imag., Apr 2019Light detection and ranging (Lidar) single-photon devices capture range and intensity information from a three-dimensional (3-D) scene. This modality enables long range 3-D reconstruction with high range precision and low laser power. A multispectral single-photon Lidar system provides additional spectral diversity, allowing the discrimination of different materials. However, the main drawback of such systems can be the long acquisition time needed to collect enough photons in each spectral band. In this work, we tackle this problem in two ways: first, we propose a Bayesian 3-D reconstruction algorithm that is able to find multiple surfaces per pixel, using few photons, i.e., shorter acquisitions. In contrast to previous algorithms, the novel method processes jointly all the spectral bands, obtaining better reconstructions using less photon detections. The proposed model promotes spatial correlation between neighbouring points within a given surface using spatial point processes. Secondly, we account for different spatial and spectral subsampling schemes, which reduce the total number of measurements, without significant degradation of the reconstruction performance. In this way, the total acquisition time, memory requirements and computational time can be significantly reduced. The experiments performed using both synthetic and real single-photon Lidar data demonstrate the advantages of tailored sampling schemes over random alternatives. Furthermore, the proposed algorithm yields better estimates than other existing methods for multi-surface reconstruction using multispectral Lidar data.
-
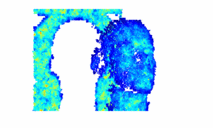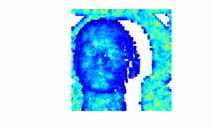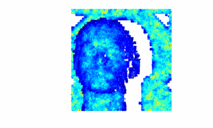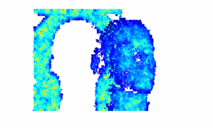 Bayesian 3D Reconstruction of Complex Scenes from Single-Photon Lidar DataJulian Tachella, Yoann Altmann , Ximing Ren , Angus McCarthy , Gerald Buller , Steve McLaughlin , and Jean-Yves TourneretSIAM Journal on Imaging Sciences, Apr 2019
Bayesian 3D Reconstruction of Complex Scenes from Single-Photon Lidar DataJulian Tachella, Yoann Altmann , Ximing Ren , Angus McCarthy , Gerald Buller , Steve McLaughlin , and Jean-Yves TourneretSIAM Journal on Imaging Sciences, Apr 2019Light detection and ranging (Lidar) data can be used to capture the depth and intensity profile of a 3D scene. This modality relies on constructing, for each pixel, a histogram of time delays between emitted light pulses and detected photon arrivals. In a general setting, more than one surface can be observed in a single pixel. The problem of estimating the number of surfaces, their reflectivity and position becomes very challenging in the low-photon regime (which equates to short acquisition times) or relatively high background levels (i.e., strong ambient illumination). This paper presents a new approach to 3D reconstruction using single-photon, single-wavelength Lidar data, which is capable of identifying multiple surfaces in each pixel. Adopting a Bayesian approach, the 3D structure to be recovered is modelled as a marked point process and reversible jump Markov chain Monte Carlo (RJ-MCMC) moves are proposed to sample the posterior distribution of interest. In order to promote spatial correlation between points belonging to the same surface, we propose a prior that combines an area interaction process and a Strauss process. New RJ-MCMC dilation and erosion updates are presented to achieve an efficient exploration of the configuration space. To further reduce the computational load, we adopt a multiresolution approach, processing the data from a coarse to the finest scale. The experiments performed with synthetic and real data show that the algorithm obtains better reconstructions than other recently published optimization algorithms for lower execution times.
-
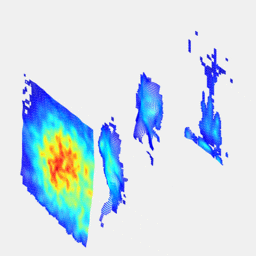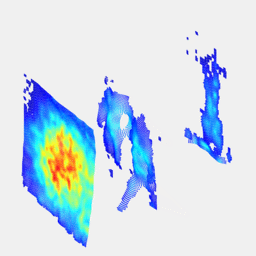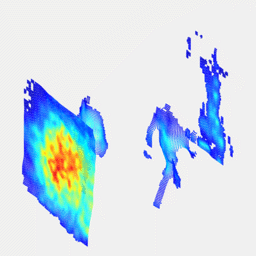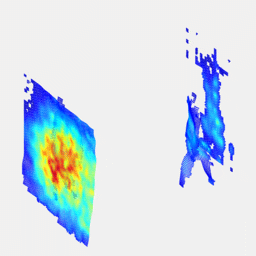 Real-time 3D reconstruction from single-photon lidar data using plug-and-play point cloud denoisersJulian Tachella, Yoann Altmann , Nicolas Mellado , Rachel Tobin , Angus McCarthy , Gerald Buller , Jean-Yves Tourneret , and Steve McLaughlinNature Communications, Apr 2019
Real-time 3D reconstruction from single-photon lidar data using plug-and-play point cloud denoisersJulian Tachella, Yoann Altmann , Nicolas Mellado , Rachel Tobin , Angus McCarthy , Gerald Buller , Jean-Yves Tourneret , and Steve McLaughlinNature Communications, Apr 2019Single-photon lidar has emerged as a prime candidate technology for depth imaging through challenging environments. Until now, a major limitation has been the significant amount of time required for the analysis of the recorded data. Here we show a new computational framework for real-time three-dimensional (3D) scene reconstruction from single-photon data. By combining statistical models with highly scalable computational tools from the computer graphics community, we demonstrate 3D reconstruction of complex outdoor scenes with processing times of the order of 20 ms, where the lidar data was acquired in broad daylight from distances up to 320 metres. The proposed method can handle an unknown number of surfaces in each pixel, allowing for target detection and imaging through cluttered scenes. This enables robust, real-time target reconstruction of complex moving scenes, paving the way for single-photon lidar at video rates for practical 3D imaging applications.
-
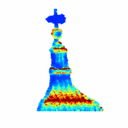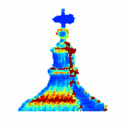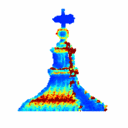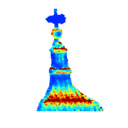 3D Reconstruction Using Single-photon Lidar Data Exploiting the Widths of the ReturnsJulian Tachella, Yoann Altmann , Stephen McLaughlin , and Jean-Yves TourneretIn Proc. Int. Conf. on Acoustics, Speech and Signal Process. (ICASSP) , May 2019
3D Reconstruction Using Single-photon Lidar Data Exploiting the Widths of the ReturnsJulian Tachella, Yoann Altmann , Stephen McLaughlin , and Jean-Yves TourneretIn Proc. Int. Conf. on Acoustics, Speech and Signal Process. (ICASSP) , May 2019 - On fast object detection using single-photon lidar dataJulian Tachella, Yoann Altmann , Stephen McLaughlin , and Jean-Yves TourneretIn Proc. SPIE Wavelets and Sparsity XVIII , Sep 2019
Light detection and ranging (Lidar) systems based on single-photon detection can be used to obtain range and reflectivity information from 3D scenes with high range resolution. However, reconstructing the 3D surfaces from the raw single-photon waveforms is challenging, in particular when a limited number of photons is detected and when the ratio of spurious background detection events is large. This paper reviews a set of fast detection algorithms, which can be used to assess the presence of objects/surfaces in each waveform, allowing only the histograms where the imaged surfaces are present to be further processed. The original method we recently proposed is extended here using a multiscale approach to further reduce the computational complexity of the detection process. The proposed methods are compared to state-of-the-art 3D reconstruction methods using synthetic and real single-photon data and the results illustrate their benefits for fast and robust target detection.





